Export / import spongram-brain/v1
Un fichier JSON versionné contient tout le cerveau. Réimporté ailleurs, chaque épisode est ré-extrait et re-daté — rien n'est écrasé, rien n'est perdu.
Mémoire seconde pour Claude Code & Claude Desktop
Chaque conversation nourrit un graphe de connaissances vivant — extrait, consolidé et rappelé par vos modèles, sur votre infra. Exportable en un clic. Zéro lock-in, zéro fuite.
Export cloud → import desktop : chaque souvenir est ré-extrait et re-daté en ~10 secondes. Format spongram-brain/v1, portable d'une instance à l'autre.
Extraction, embeddings, consolidation : tout tourne sur vos GPUs, sur votre infra — jamais un tiers.
Chaque entité est un nœud du Cortex 3D, mis à jour en direct par SSE à chaque nouvelle mémoire.
Produit, explorateurs et admin entièrement bilingues — parité de traduction vérifiée clé par clé.
Portabilité
Le cerveau entier — épisodes, entités, faits datés — s'exporte et se réimporte au format ouvert spongram-brain/v1. Aucune donnée n'est prisonnière de l'instance qui l'a créée.
Un fichier JSON versionné contient tout le cerveau. Réimporté ailleurs, chaque épisode est ré-extrait et re-daté — rien n'est écrasé, rien n'est perdu.
Exportez depuis l'admin cloud, importez dans l'app desktop (ou l'inverse) : le format est identique des deux côtés, la migration ne demande aucun script.
L'édition Desktop embarque une carte Sauvegarde dédiée dans les réglages — export planifiable, restauration en un clic, aucune base externe requise.
Entité, fait ou instance entière : vous choisissez ce qui reste. Zéro rétention forcée, zéro export bridé.
Le poste de commande
Quatre écrans réels de l'admin cloud en production — dark-first, dôme Cortex vivant, explorateurs plein écran.

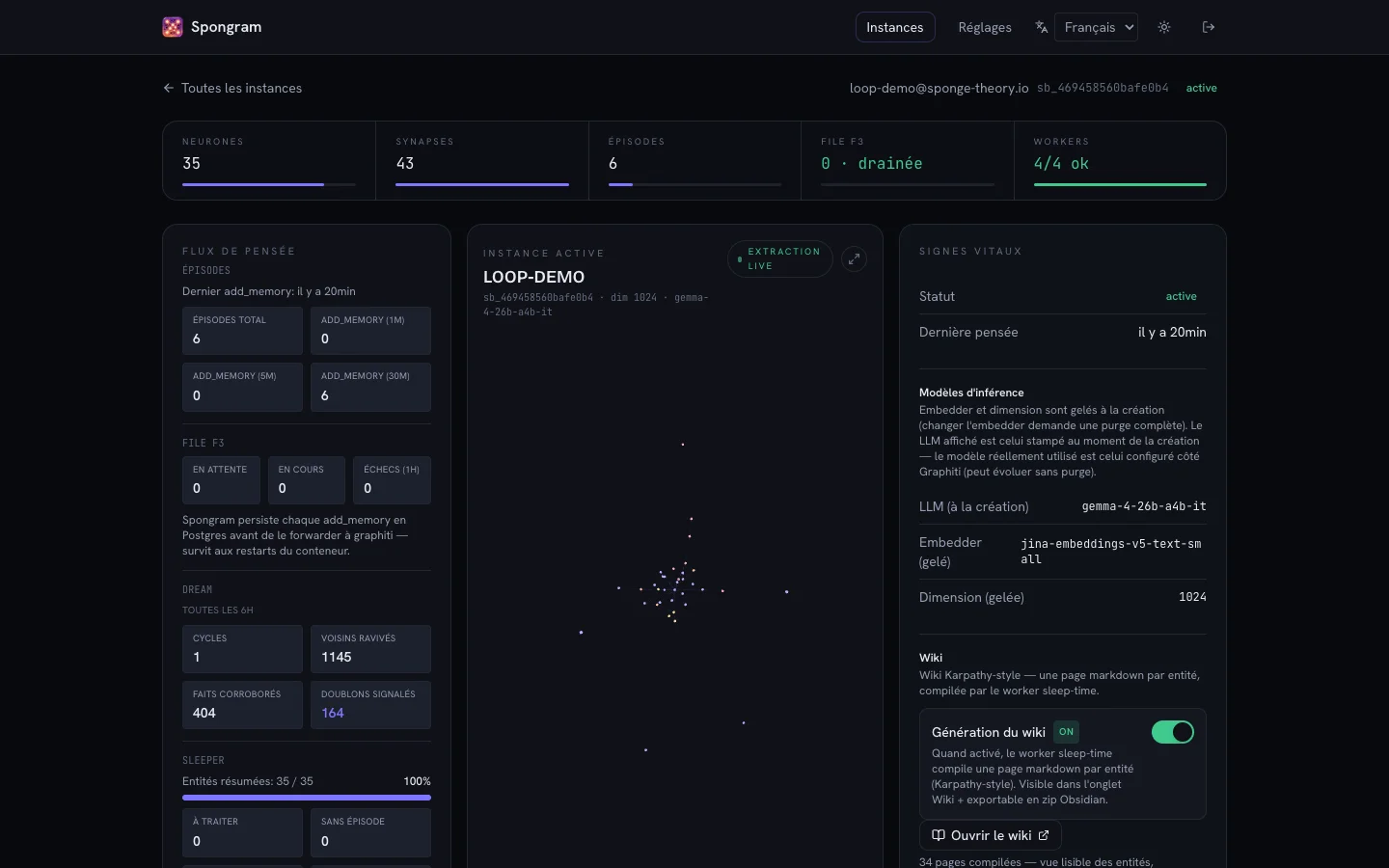
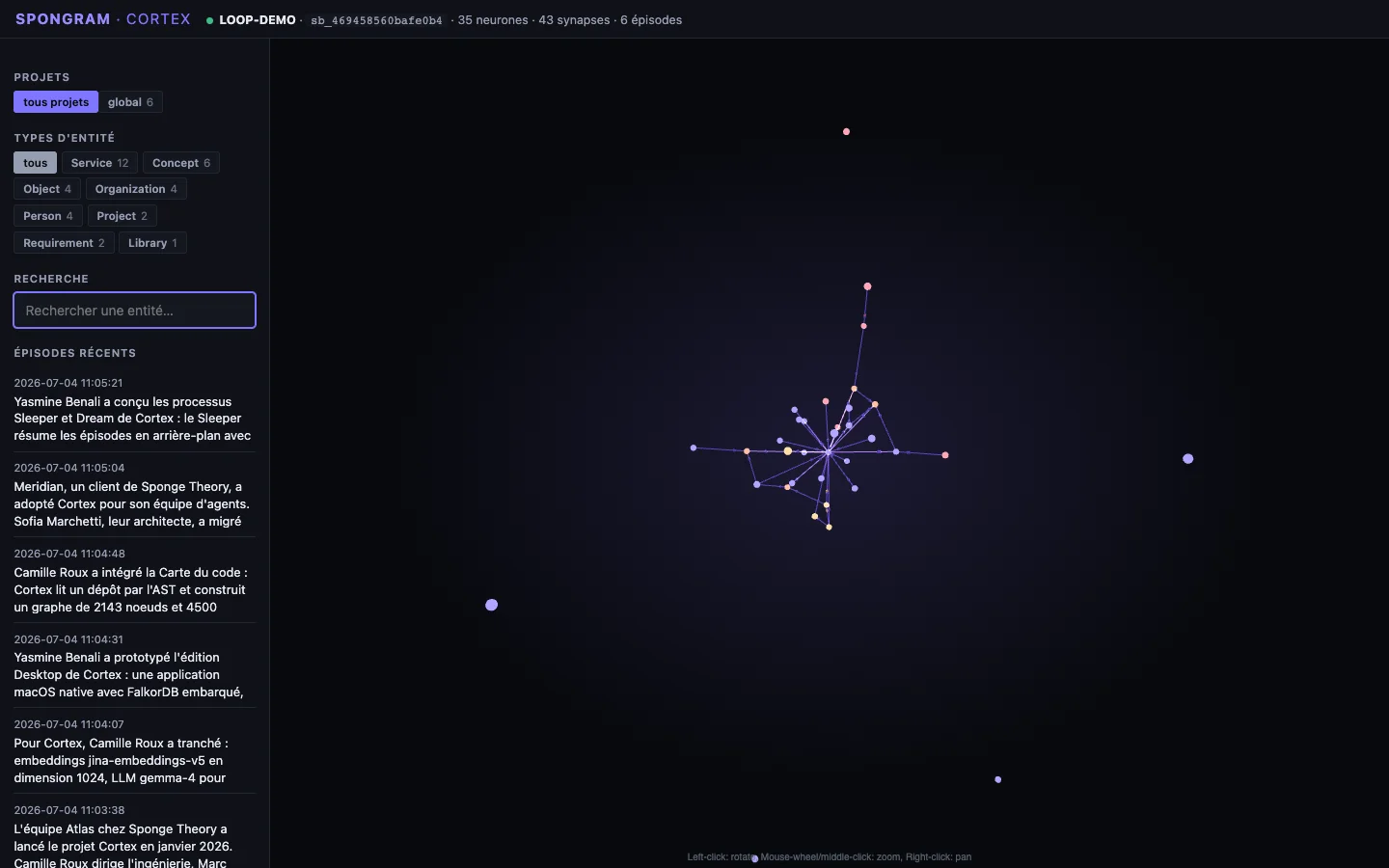
Création d'un cerveau, installation du plugin Claude Code, première mémoire ajoutée puis rappelée, vue Cortex 3D en direct, export cloud → import desktop cross-instance, explorateurs en plein écran et sauvegarde desktop — capturé sur le produit réel, pas une maquette.
Postgres + Neo4j + Graphiti + LLM auto-hébergés. Aucun token d'épisode ne sort de votre réseau. Compatible Docker Swarm ou compose simple.
Isolation stricte par `group_id` injecté côté serveur, anti-tampering. Une instance, N cerveaux, zéro fuite croisée.
Bundle `.plugin` généré à la volée par tenant : marketplace, SKILL.md, hook SessionStart. `claude plugin install spongram` et la mémoire est là.
Chaque fait porte `valid_at` / `invalid_at`. Quand vous corrigez une info, l'ancienne version est superseded — l'historique reste auditable.
Ollama, LM Studio, vLLM local, OpenAI, Anthropic, Mistral, Groq ou n'importe quel endpoint OpenAI-compat. Switch à chaud depuis l'admin, zéro restart, zéro lock-in. Validation 3-layer (chat / tool_calls / json_schema strict) en un clic.
Extraction AST déterministe (tree-sitter) de vos repos → graphe structurel multi-tenant interrogeable par 5 outils MCP. Mesuré en banc réel : −68% de coût sur les questions d'architecture, ~2× plus rapide que grep/read.
Toutes les capacités listées ici sont vérifiables dans le code livré.
Spongram cartographie vos repos par AST (tree-sitter) et expose le graphe à Claude Code via 5 outils MCP. Tout ce qui suit est mesuré en sessions claude -p réelles, sur le repo de Spongram lui-même — protocole et runner livrés avec le produit (docs/BENCH_CODEMAP_2026-06-10.md).
| Question de navigation de code | Sans Spongram (grep/read) | Avec Spongram (code-map) | Δ coût |
|---|---|---|---|
| Fichiers / symboles les plus centraux | $0.329 — sous-agent + 29 greps, classement estimé | $0.105 — 1 appel god_nodes, degré exact du graphe | −68 % |
| Vue d'ensemble d'un package | $0.291 | $0.178 | −39 % |
| Qui appelle cette fonction ? | $0.086 | $0.106 — appelants prod + tests en 1 appel | +23 %* |
| Contenu d'un module (classes, méthodes) | $0.128 | $0.181 | +41 %* |
| Chemin de dépendance A → B | $0.107 | $0.129 | +20 %* |
| Total (6 questions) | $1.05 | $0.83 | −21 % |
| Temps de réponse cumulé | 293 s | 151 s | −48 % |
* Sur le ponctuel, grep reste moins cher — et c'est exactement ce que la SKILL livrée dit à l'agent : chaque outil à sa place. Banc A/B en sessions claude -p réelles (Sonnet), 1 question par session, outils en lecture seule, repo de 276 fichiers ; total entre −12 % et −21 % selon les runs.
tree-sitter côté client (~30 langages) : 276 fichiers → 2 143 nœuds / 4 509 arêtes en ~14 s. Aucun coût d'indexation, résultat reproductible au commit près.
code_map_query, neighbors, god_nodes, shortest_path, stats — y compris les appels qualifiés module.attr() inférés par AST, que grep rate souvent.
~110 tokens injectés à l'ouverture : taille du repo, dossiers, fichiers centraux. L'agent est orienté avant son premier appel d'outil.
Un souvenir qui cite un fichier ou un symbole remonte automatiquement ses nœuds de code dans search_nodes. La carte reste fraîche via le hook git post-commit.
Onglet 3D « Carte du code » ; graphe portable Neo4j (cloud) / FalkorDB embarqué (desktop), isolé par tenant.
Spongram parle OpenAI-compat. 9 presets, plus un mode Custom pour n'importe quel endpoint. Changement à chaud depuis l'admin, validation 3-layer intégrée.
Tous gérés par la même page admin Settings. Bouton « Tester la connexion » → 3-layer probe (chat / tool_calls / json_schema strict) → vous savez en 3 secondes si votre provider est Graphiti-compatible.
Une seule instance FastAPI sert le MCP, l'admin, l'explorateur 3D et la landing. Le reste est du Postgres et du Neo4j, hébergés côte à côte.
Achat direct via Lemon Squeezy. Même moteur de mémoire, même carte du code — choisissez où ça tourne.
Self-host multi-tenant, pour équipes et infra GPU
Licence self-host, source incluse, documentation de déploiement.
App native, 100 % offline, zéro Docker
Licence à vie par poste, activation Lemon Squeezy intégrée à l'app.
À l'achat, vous recevez les images Docker et le template d'environnement. Trois étapes, 10 minutes sur une machine avec Docker.
cp .env.example .env
# ajustez SPONGRAM_ADMIN_TOKEN + SPONGRAM_INFERENCE_API_KEY
# pointez SPONGRAM_INFERENCE_BASE_URL sur votre endpoint OpenAI-compatdocker compose up -d
# Postgres + Neo4j + Spongram démarrent ;
# migrations SQL appliquées automatiquement# Espace admin : http://localhost:8091/admin/
# créez une instance, copiez la clé spt_brain_ (affichée une seule fois)
claude marketplace add https://votre-domaine.tld/admin/api/spongram/marketplace.json
claude plugin install spongramPour la prod : Docker Swarm derrière Traefik, déploiement via Portainer. Documentation complète livrée à l'achat.
Une mémoire long-terme multi-tenant pour agents Claude. Spongram emballe Graphiti, ses bundles client, son admin et son inférence dans un produit cohérent que vous déployez chez vous.
Vous le pouvez. Si votre contrainte primaire est multi-tenant strict + 100% on-prem + intégration Claude Code en un clic, Spongram coche les trois cases en V1 avec un livrable de production. Sinon, allez vers le produit qui couvre votre besoin.
Aucun en particulier — Spongram parle OpenAI-compat. Vous choisissez votre provider depuis l'admin (dropdown 9 presets : SPT Models, Ollama, LM Studio, vLLM local, OpenAI, Anthropic via adapter, Mistral, Groq, ou Custom). Switch à chaud, zéro restart. Une probe 3-layer valide que votre provider supporte tool_calls + json_schema strict avant que vous ne sauvegardiez.
Sur les questions structurelles, beaucoup : « quels sont les fichiers centraux » coûte −68% (un appel code_map_god_nodes remplace un sous-agent + 29 greps, et donne la seule réponse exacte), une vue d'ensemble de package −39%. Sur l'ensemble d'un banc de 6 questions réelles : ≈ −17% de coût et ~2× plus rapide. Sur un simple « où est défini X », grep reste moins cher — et c'est ce que la SKILL dit à l'agent. Chiffres et protocole reproductibles livrés avec le produit.
Deux éditions en achat direct via Lemon Squeezy : Spongram Desktop (licence à vie par poste — macOS disponible, Windows/Linux en préparation) et Spongram Cloud (licence self-host, source incluse). Pour un déploiement accompagné, multi-site ou des volumes : contact@sponge-theory.ai.